LLMWhisperer v2: FAQs
We added a tonne of practical, powerful and interesting list of features (see below) to LLMWhisperer v2. However, there is one reason why we were't able to add these new features to the same service that runs v1 as additional improvements: the developer experience or DX. LLMWhisperer v1's developer portal is super limiting since it's based on Azure's APIM and we had very little control over it.
We've always wanted a useful dashboard, a powerful playground and an easy way for our users to manage their accounts. This was just not possible with the barebones portal we could built with APIM.
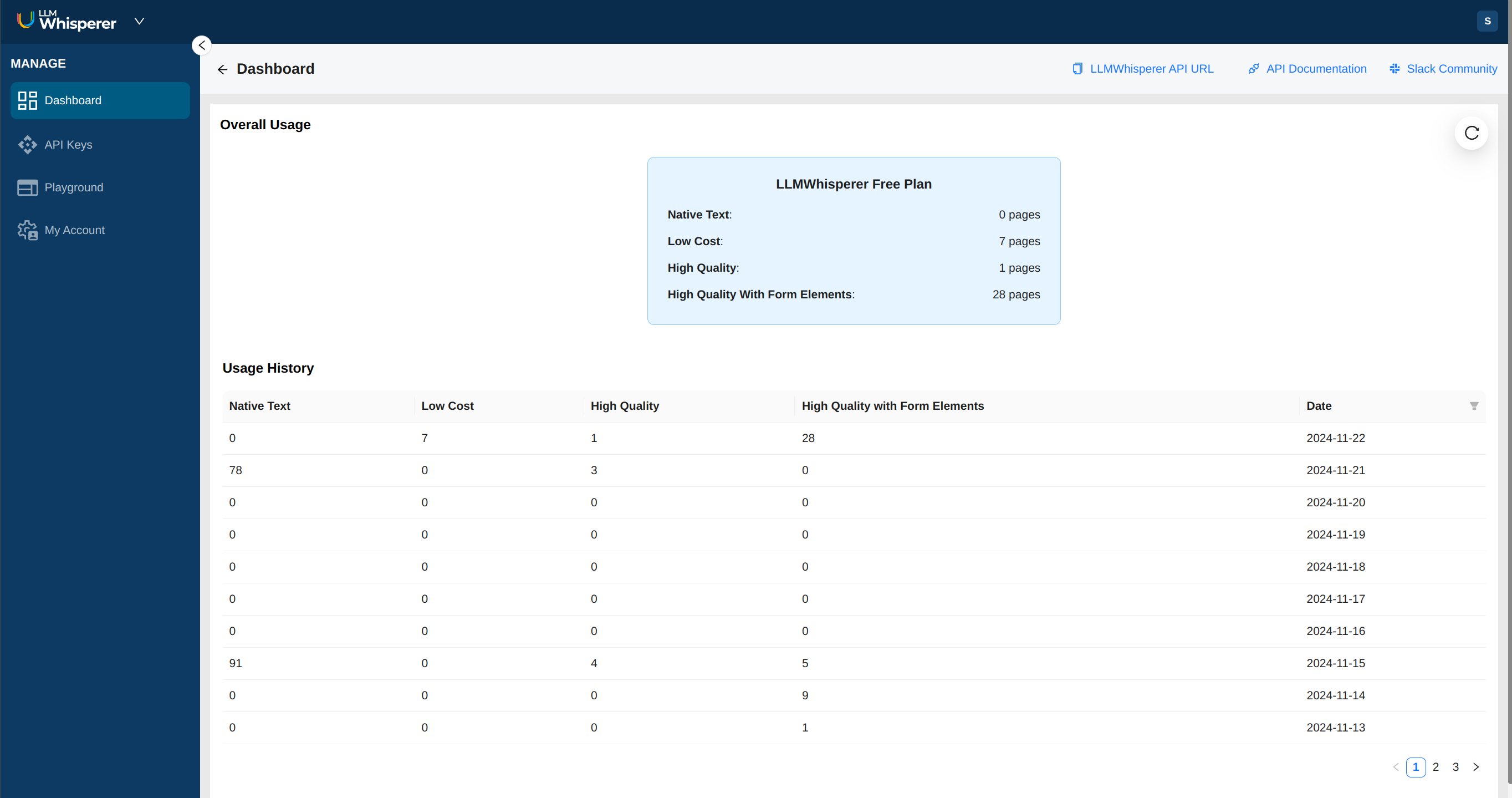
Thus, when we built v2, we also moved to our own, custom developer portal which is fully built out with a dashboard, a playground and a simple, pay-as-you-go pricing model with no up-front commitment needed.
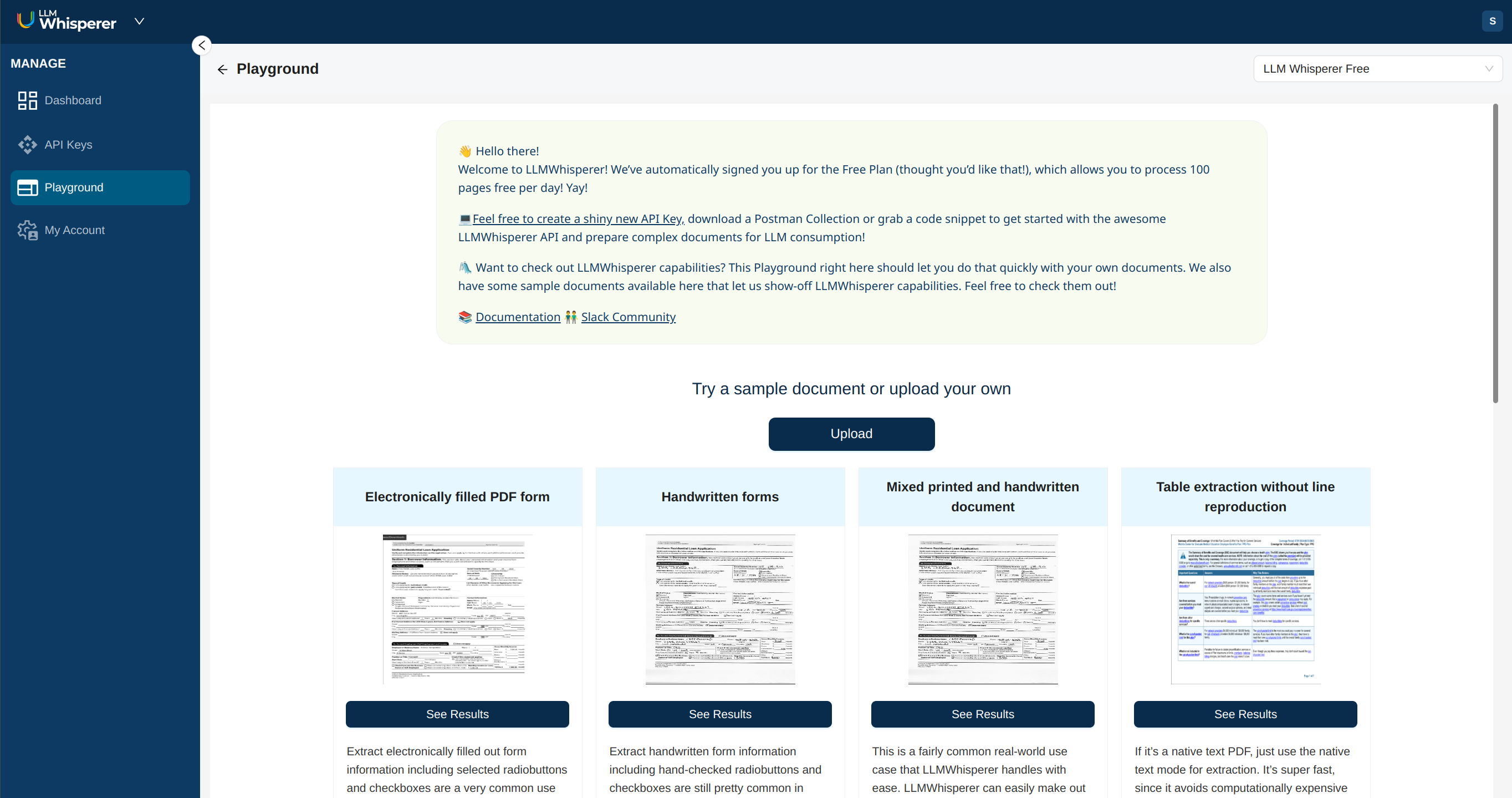
One small inconvenience of this switch to the new Developer Portal is that you'll need to create a new account for v2 and make trivial changes to your code to use the v2 Python client.
What's new in LLMWhisperer v2?
- Parallel page processing: In v1, when you sent a document for processing, it would process pages in it sequentially. LLMWhisperer v2 fans out to process pages in your document in parallel, saving you time.
- Webhooks support: No need to poll for the status of long-running jobs anymore. Simply register a webhook and get a callback once your document is done processing for more elegant extraction of your documents.
- ASCII Table Line Separators: Columns and rows close to each other confusing LLMs? This feature draws ASCII lines for table columns and rows, clearly demarcating them, giving LLM responses a huge accuracy boost. Works well with merged columns and rows!
- Simplified and improved Highlighting support: Source document highlighting is very important should you need to have humans efficiently review extractions. LLMWhisperer v2 has a simplified and easy to use Highlighting Support API and related functions in the Python client. This is done in collaboration with an extractor LLM.
- Document Layout Metadata Support: (Experimental) LLMWhisperer v2 returns metadata about the general layout of the document being extracted. It contains information about the sections and sub sections. This information can be used for smart chunking of the document for LLMs. This is under active development and will be improved over time. This will also be core of or smart chunking feature coming soon. Note that this feature is experimental and is subject to change.
- Line Splitter Strategy Control: Advanced parameters for better control of some aspects of the conversion. This is useful when you need to customize the line splitting process. Some documents do not have lines of text that do not align with the rest of the text. For example vertically center aligned text in a table cell will be offset from the text in the next cell. This parameter can be used to control the line splitting process. It provides options to set the priority of the direction (left, right and center) to look for to align the text. In most cases, this is chosen automatically. But in some cases, you might want to control this.
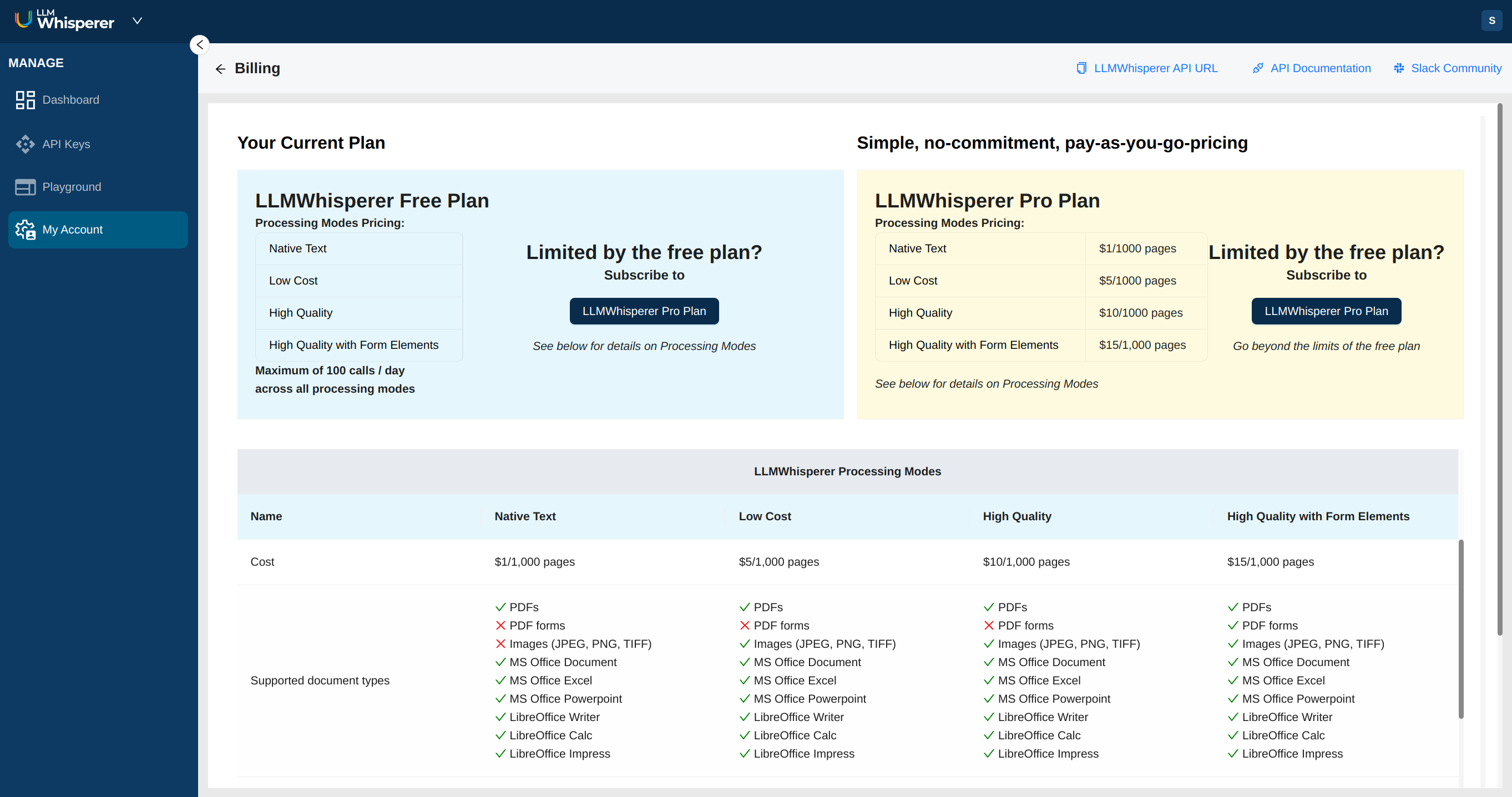
- Up to 1/5th the cost of v1: Super low cost extraction with fine-grained control of the processing modes and costs.
- Pay-as-you-go billing model: No more tiers and up-front costs. Just pay for what you use.
What's the new LLMWhisperer v2 pricing?
Please see the LLMWhisperer section of the pricing page on our website for detailed pricing vis-a-vis features.
Which regions is LLMWhisperer v2 available in?
Both Unstract and LLMWhisperer are available in the US Central and EU West regions.
Is LLMWhisperer v2 available as an on-prem offering?
Yes, it is available to be installed on your own VPC on AWS, GCP or Azure. Please contact us for more details.
I'm an LLMWhisperer v1 paying customer. How can I move to LLMWhisperer v2?
By moving to LLMWhisperer v2, given the significantly lower cost and pay-as-you-go billing model, you can save a lot, while not spending on tier costs that you might not use. Not to mention, you'll enjoy blazing performance and very useful new features that can give your LLM response accuracy a boost.
Moving to LLMWhisperer v2 is super simple by following these steps:
- Sign up for LLMWhisperer v2. You get free 100 pages/day as part of our forever-free plan. This should hopefully be enough for your testing.
- Move your code to call LLMWhisperer v2 with the new version of the Python client. Changes will be super minimal when you use the Python client!
- Optionally, take advantage of any new features mentioned above and don't forget to test!
- Wait for the end of the month for your v1 billing cycle to come to a close and cancel the v1 plan, while subscribing to the v2 pay-as-you-go plan from the new, easy to use Developer Portal.
Code changes needed to move from v1 to v2
We've kept the calling signatures as similar as we can so you can get going quickly.
US and EU servers API endpoints
US
https://llmwhisperer-api.us-central.unstract.com/api/v2
EU
https://llmwhisperer-api.eu-west.unstract.com/api/v2
Python client
The main class is now LLMWhispererClientV2 instead of LLMWhispererClient. Apart from this, the calling signatures are the same. Make sure you create an instance of LLMWhispererClientV2 instead of LLMWhispererClient.
Methods removed in v2:
highlight_data()
New methods added in v2:
get_highlight_rect()- A more advanced highlighting API that returns the bounding boxes and other metadata for highlighting in the source document.register_webhook()- Register a webhook to get a callback when your document is done processing.get_webhook_details()- Get details of a webhook you've registered.
Javascript client
V2 of the Javascript client is in the works and will be released soon. Stay tuned!