LLMWhisperer Text Extractor-v2
LLMWhisperer is a text extraction service that extracts and presents data from complex documents (different designs and formats) to LLMs in a way that they can best understand.
Advantages of using LLMWhisperer v2:
- The main benefit is parallel page processing, which results in faster extraction of large documents.
- Webhooks are introduced to notify once extraction is complete.This will be useful when LLMWhisperer v2 API is used separately.
Getting started with LLMWhisperer Text Extractor-v2
When you sign up for LLM whisperer-v2, you will be provided with lifetime free access with a limit of 100 pages per day.
-
Sign-up for an LLM Whisperer account and choose the product as "LLM Whisperer"
-
Click on "Get Started" to start the free subscription to LLM Whisperer account

-
Click on "API Keys" and copy the
LLM Gateway URLandAPI Keyas shown below.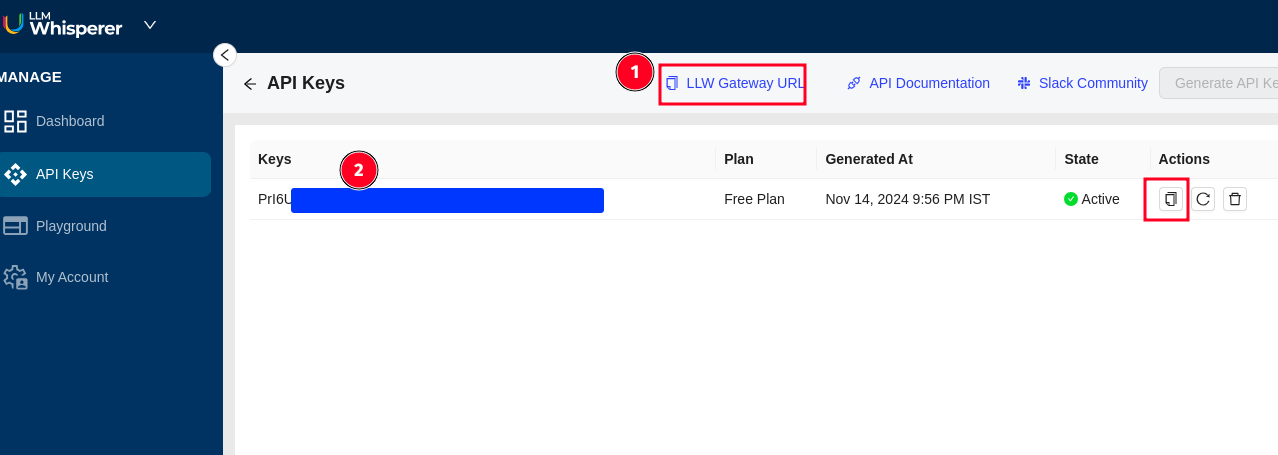
Setting up the LLM Whisperer connector in Unstract
Now that we have an API key from LLM Whisperer, we can use it to set up a Text Extractor profile on the Unstract platform. For this:
-
Sign in to the Unstract Platform
-
From the side navigation menu, choose
Settings🞂Text Extractor -
Click on the
New Text Extractorbutton. -
From the list of Text Extractor, choose
LLMWhisperer V2. You should see a dialog box where you enter details.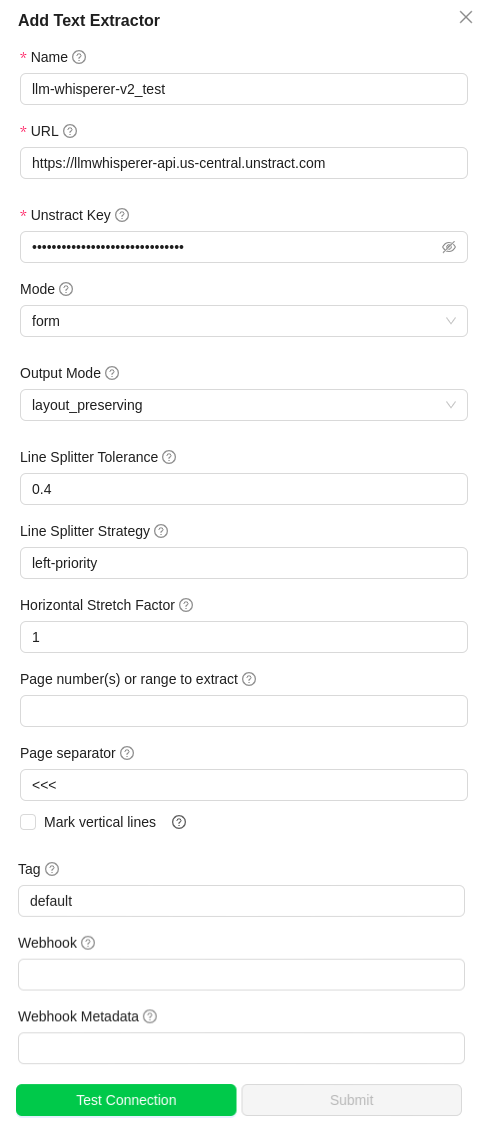
-
For
Name, enter a name for this connector. -
Leave the
URLfield to the default value. -
In
Unstract Key, enter thekeycreated in the above section. -
In
Mode, chooseNative Text- To process text based files.Low Cost- To process high quality pdf documents.High Quality- To process Medium/low quality scanned PDFs and Handwritten documents.Form- To process pdf with Checkbox and radio button detection- Check the below image for the comparison of modes
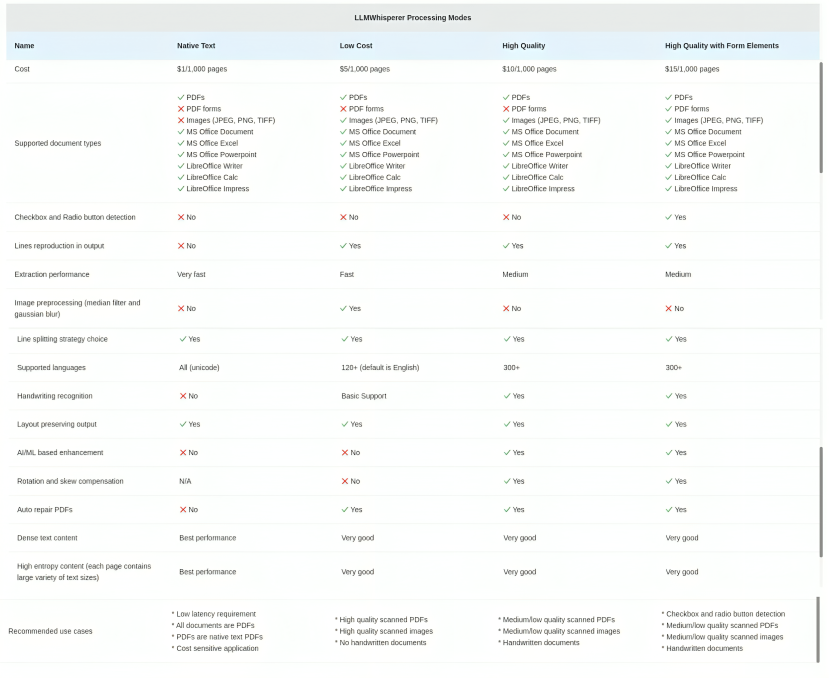
-
In
Output Mode, chooselayout_preserving- To extract the text line by line.text- Keeps the context of the document in place.
-
Line Splitter Tolerance- Default value is 0.4 .Reduce this value to split lines less often, increase to split lines more often. Useful when PDFs have multi-column layout with text in each column that is not aligned. -
Horizontal Stretch Factor- Default value is 1 .Increase this value to stretch text horizontally, decrease to compress text horizontally. Useful when multi-column text merge with each other. -
Page number(s) or range to extract- Specify the range of pages to extract (e.g., 1-5, 7, 10-12, 50-). Leave it empty to extract all pages. -
Page separator- Specify a pattern to separate the pages in the document(e.g., <<< {{page_no}} >>>, <<< >>>). This pattern will be inserted at the end of every page. Omit page_no if you don't want to include the page number in the separator. -
Mark Vertical Lines&Mark Horizonatal Lines- Both buttons must be in the same state (either both checked or both unchecked) for the operation to proceed.
- If checked, it will extract the tables structure(border and internal lines) with dotted lines.Check this buttons if the table is outlined properly in the document.
-
Leave other values to its default.
-
Click on
Test Connectionand ensure it succeeds. You can finally click onSubmitand that should create a new Text Extractor Profile for use in your Unstract projects.