Setting up LLM profiles
Overview
Unstract provides a sample profile with pre-configured LLM, embedding, vectorDB, and Text Extractor components with a quota of 1 million tokens. Users can also configure their own custom LLM profiles with preferred components.
Accessing LLM Profile Settings
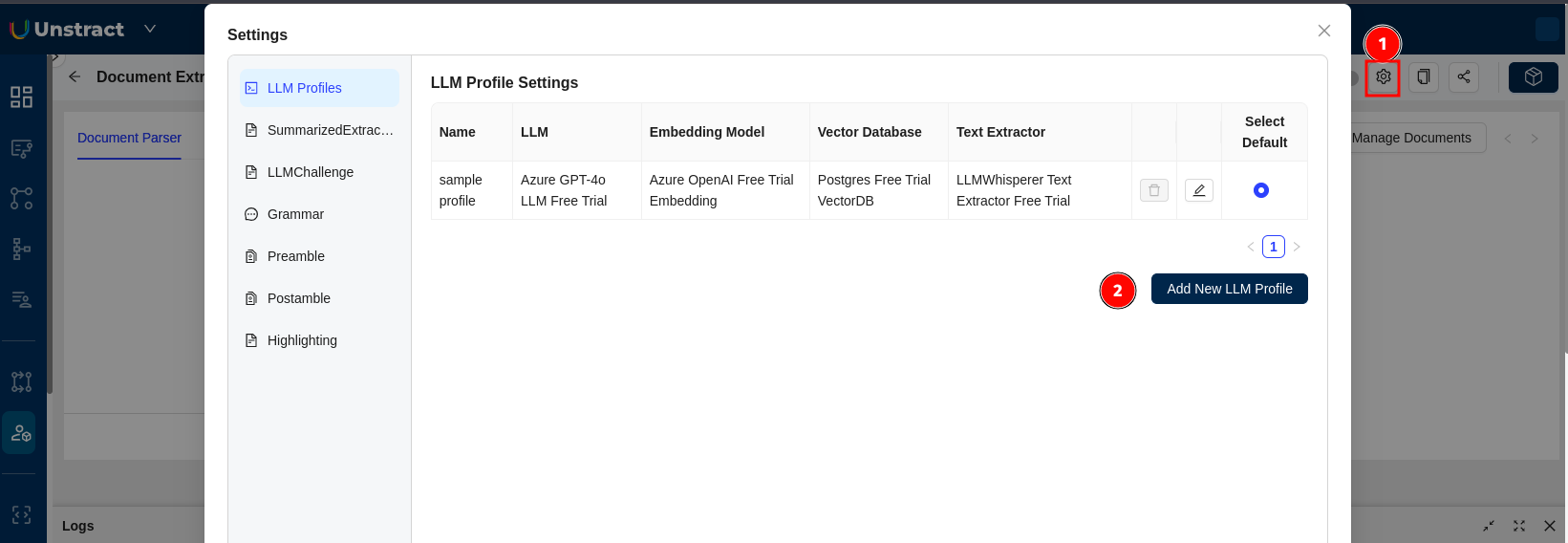
- Click on the Settings gear icon (⚙️) in the top-right corner of the Unstract interface.
- In the Settings menu, select "LLM Profiles" from the left sidebar.
Default Sample Profile
By default, Unstract provides a sample profile with the following pre-configured components:
- Name: sample profile
- LLM: Azure GPT-4o LLM Free Trial
- Embedding Model: Azure OpenAI Free Trial Embedding
- Vector Database: Postgres Free Trial VectorDB
- Text Extractor: LLMWhisperer Text Extractor Free Trial
Creating a New LLM Profile
-
From the LLM Profile Settings page, click the "Add New LLM Profile" button.
-
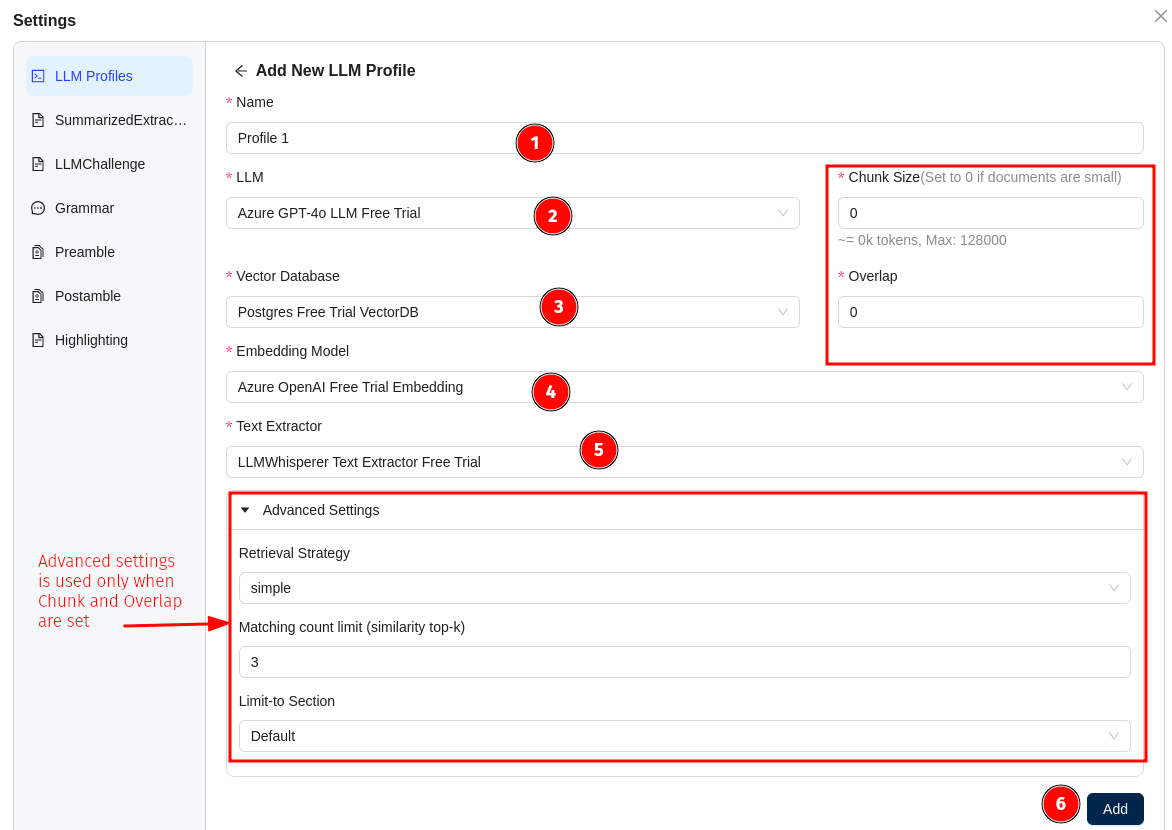
Fill in the required fields in the form:
- Name: Enter a name for your profile (e.g., "Profile 1")
- LLM: Select your preferred Language Model (e.g., Azure GPT-4o LLM Free Trial). Refer LLM's section to configure your preferred LLM.
- Vector Database: Choose your preferred vector database (e.g., Postgres Free Trial VectorDB).Refer VectorDB section to configure your preferred VectorDB.
- Embedding Model: Select your preferred embedding model (e.g., Azure OpenAI Free Trial Embedding).Refer Embedding section to configure your preferred Embedding.
- Text Extractor: Choose your preferred text extraction tool (e.g., LLMWhisperer Text Extractor Free Trial).Refer Text Extractor section to configure your preferred Text Extractor.
- Chunk Size: Set the chunk size (set to 0 if documents are small)
- Overlap: Configure the overlap value
- Before setting Chunk Size and Overlap, refer Chunk and overlap section.
-
Advanced settings are applicable only when Chunk Size and Overlap are set.
- Retrieval Strategy:
- Simple: Based on your prompt, the chunks will be retrieved.
- Subquestion: LLM will generate a set of specific subquestions from the prompt which can be used to retrieve relevant context from vector db. Fewer questions for simpler prompt, with a maximum subquestions of 10.
- Matching count Limit(Similarity top-k): Based on the count, the top number of chunks will be sent as an input context to LLM. For example if top-k is 3, then first 3 chunks will be sent to LLM as input context.
- Click the "Add" button to create your new LLM profile.
Managing LLM Profiles
- You can edit existing profiles using the edit button next to each profile.
- Set a profile as default by selecting the radio button in the "Select Default" column.