Output Analyzer
Overview
The Output Analyzer is a feature in Unstract that provides a side-by-side comparison of your original documents and the extracted data. This tool allows you to visually validate extraction accuracy, troubleshoot extraction issues, and gain confidence in the data being extracted from your documents.
Accessing the Output Analyzer
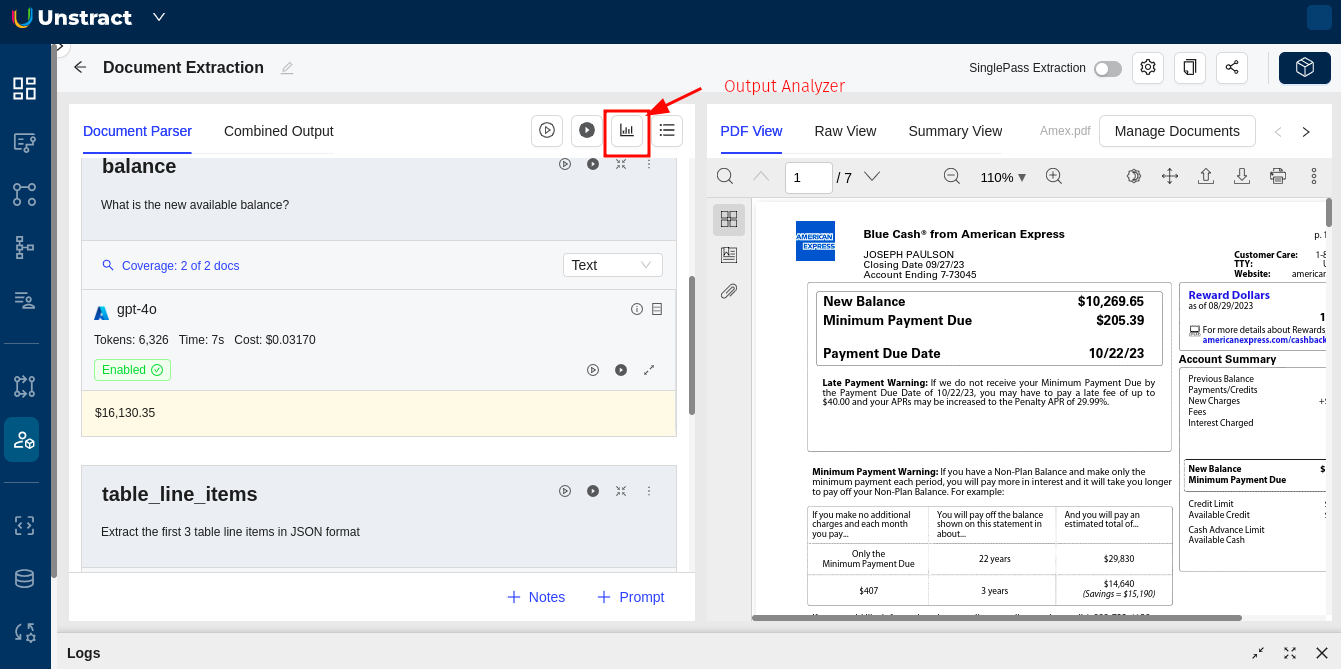
- From Document Extraction Interface:
- In the Document Extraction interface, locate the chart icon (📊) in the toolbar (highlighted with a red arrow in the first screenshot).
- Click this icon to launch the Output Analyzer.
Output Analyzer Interface
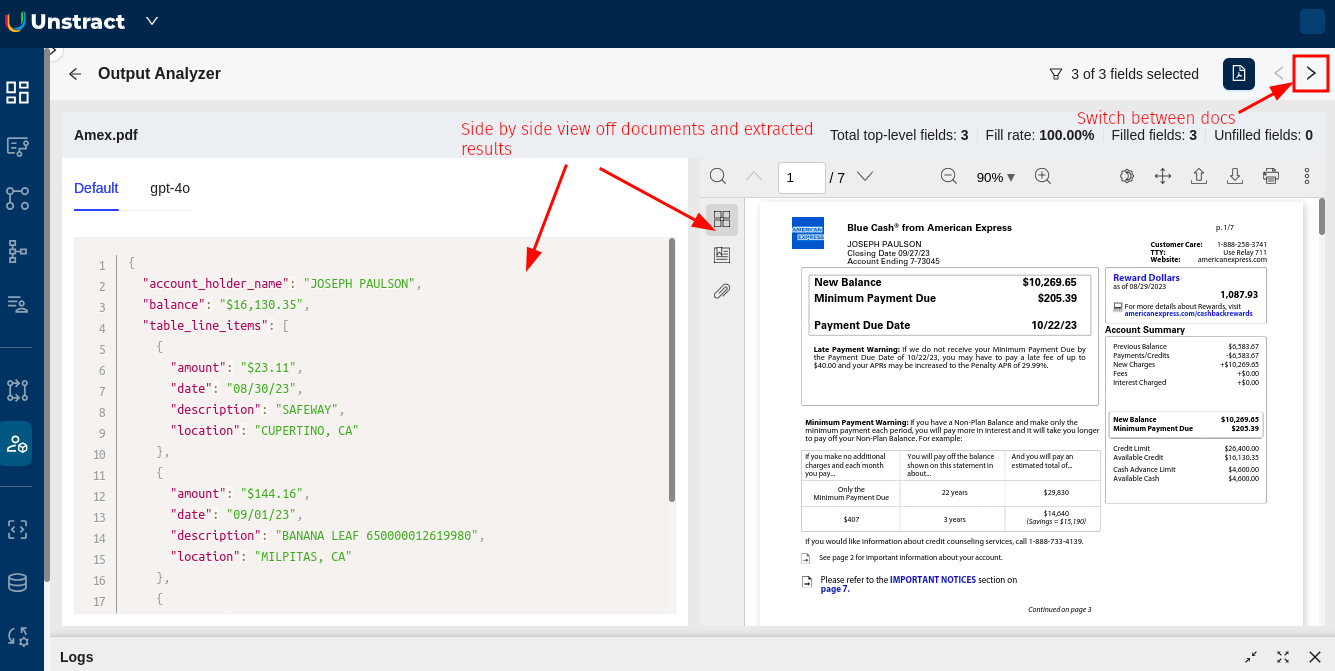
The Output Analyzer provides a split-screen view with two main components:
Left Panel: Extracted Data
- Displays the structured JSON output of all extractions
- Shows all extracted fields with proper syntax highlighting
- Includes line numbers for easy reference
- Displays the exact data that has been extracted from the document
Right Panel: Original Document
- Shows the original document in its native format
- Allows you to scroll through the document to locate source information
- Provides context for the extracted data
- Supports PDF navigation tools (zoom, page navigation, etc.)
Key Features
-
Side-by-Side Comparison:
- Directly compare extracted data with its source in the original document
- Verify accuracy of extractions visually
-
Document Navigation:
- Switch between different uploaded documents using the arrow button (>) in the top-right corner
- Review extraction results across multiple documents
-
Extraction Statistics:
- View summary statistics about your extractions:
- Total top-level fields
- Fill rate percentage
- Number of filled and unfilled fields
- View summary statistics about your extractions:
-
Field Selection Tracking:
- The interface shows how many fields are currently selected (e.g., "3 of 3 fields selected")
-
Document View Options:
- Toggle between different document viewing modes using the icons in the right panel
Use Cases
-
Quality Assurance:
- Verify that extracted data accurately reflects the content in the original document
- Identify any mismatches or extraction errors
-
Troubleshooting:
- Diagnose issues with extractions by seeing exactly where data is coming from
- Understand why certain fields might be extracted incorrectly
-
Prompt Refinement:
- Use insights from the side-by-side comparison to refine your prompts
- Identify patterns or document areas that may require special handling
-
Demonstration and Validation:
- Show stakeholders exactly how the system is extracting data
- Build confidence in the extraction process through visual validation
By effectively utilizing the Output Analyzer, you can ensure the accuracy and reliability of your document extractions, leading to higher quality data and more confident decision-making based on that data.