Prompt Studio: Introduction
Current Intelligent Document Processing or IDP system are based on classical machine learning and NLP technology and have several, very limiting disadvantages:
- The most difficult part of current IDP systems is manually annotating fields for extraction.
- Handling variations within the same document type needs more manual annotations. The more different the variants look, the more annotations are needed.
- There is a need to create a "training set" manually to identify and deal with document variants.
- Dealing with extraction of fields from documents that involve natural language text, not just from simple documents like invoices/passports/driver’s licenses/standard forms is either exceedingly cumbersome or outright impossible in practice
- Accurately extracting structured data from documents that may be dozens of pages long with the information to be extracted scattered across the document is a huge challenge even with features like Segmentation.
- The need for post-processing is very common. Date formats, stripping out of extra characters need to be handled separately.
Let's call these IDP 1.0 systems.
Intelligent Document Processing 2.0
By leveraging the power of Large Language Models, computers can deal with unstructured documents not unlike how humans deal with them—with natural language.
Given the input or source document, prompts that describe what fields to extract, how to format them and the schema to output the response in, we can indeed achieve structured data extraction from unstructured documents pretty much how a human would approach it. This was not possible before LLMs became commonplace. In essence, we’re relying on two powerful attributes Large Language Models have to achieve structured data extraction from unstructured documents:
- Their ability to reason
- They ability to follow instructions
With these abilities as a foundation, Large Language Models usher in the era of IDP 2.0.
A purpose-build prompt engineering environment
Central to the concept of Large Language Models enabling IDP 2.0 is the ability to use prompt engineering so we can:
- Extract the fields we need from unstructured documents while also formatting them with just the use of natural language.
- Specify a schema for the extraction through the use of prompt engineering.
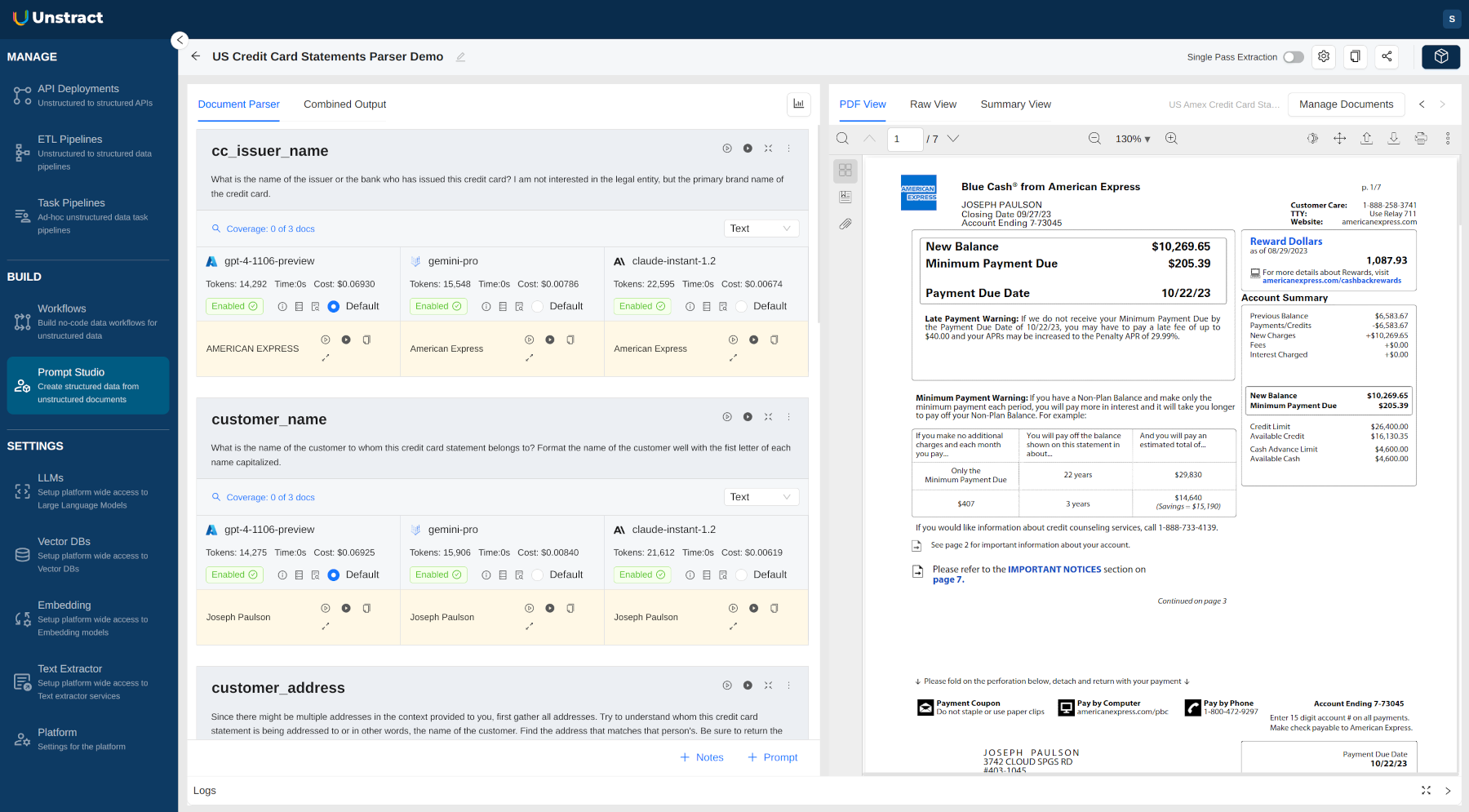
In subsequent sections, let's look at Prompt Studio in detail.