Calculating extraction costs
As a customer planning to use Unstract to extract structured data from unstructured documents, you might want to be sure about total cost of ownership. While it's easy to understand how much the Unstract Cloud or Unstract On-Prem editions might cost for the kind of volume you expect to deal with, calculating how much you might expect to spend on Large Language Models is a little bit more involved, but fairly easy and straightforward to calculate.
Components of the total cost
The full cost of extracting structured data using the Unstract platform can be arrived at by adding up the following costs:
- Cost of the Unstract platform (usually per page processed)
- Cost of the text extraction service (e.g: LLMWhisperer; usually per page processed)
- Cost of the extraction LLM (number of tokens consumed).
- Cost of the challenger LLM (number of tokens consumed).
- Cost of the embedding model. This is usually a tiny fraction and can ignored for all practical purposes.
Cost of items 3-5 depends on the average lengths of the documents being processed, the number of fields being extracted, etc.
Calculating total cost
One convenient way to calculate total cost is by following the procedure outlined below:
- Deploy your Prompt Studio project as an API.
- Enable API metadata and run extractions for 10-15 files. Ensure that when you choose these sample files, they're a good representative sample set of the kind of variants you'll see in production. Increase the sample set size should you want to increase the accuracy of your calculation or you're likely yo see wide-ranging variants in production. Please see below for details on cost metadata as returned by API Deployment responses.
- Gather the costs of the extractor LLM, challenger LLM and embedding model. The cost of the text extraction service is easy to calculate since it's usually charged per page. You should now have the per-document total extraction costs.
- Average the per-document extraction costs and you should have a very good estimate of what extraction costs are going to be for you in production.
Cost Metadata
When you call an API Deployment RESTful API passing in an unstructured document to get structured data back, you can [enable API metadata] so that the API response includes cost and other details.
Here are details of the number of tokens consumed and cost of the extractor LLM along with the cost of the embedding model for this particular document:
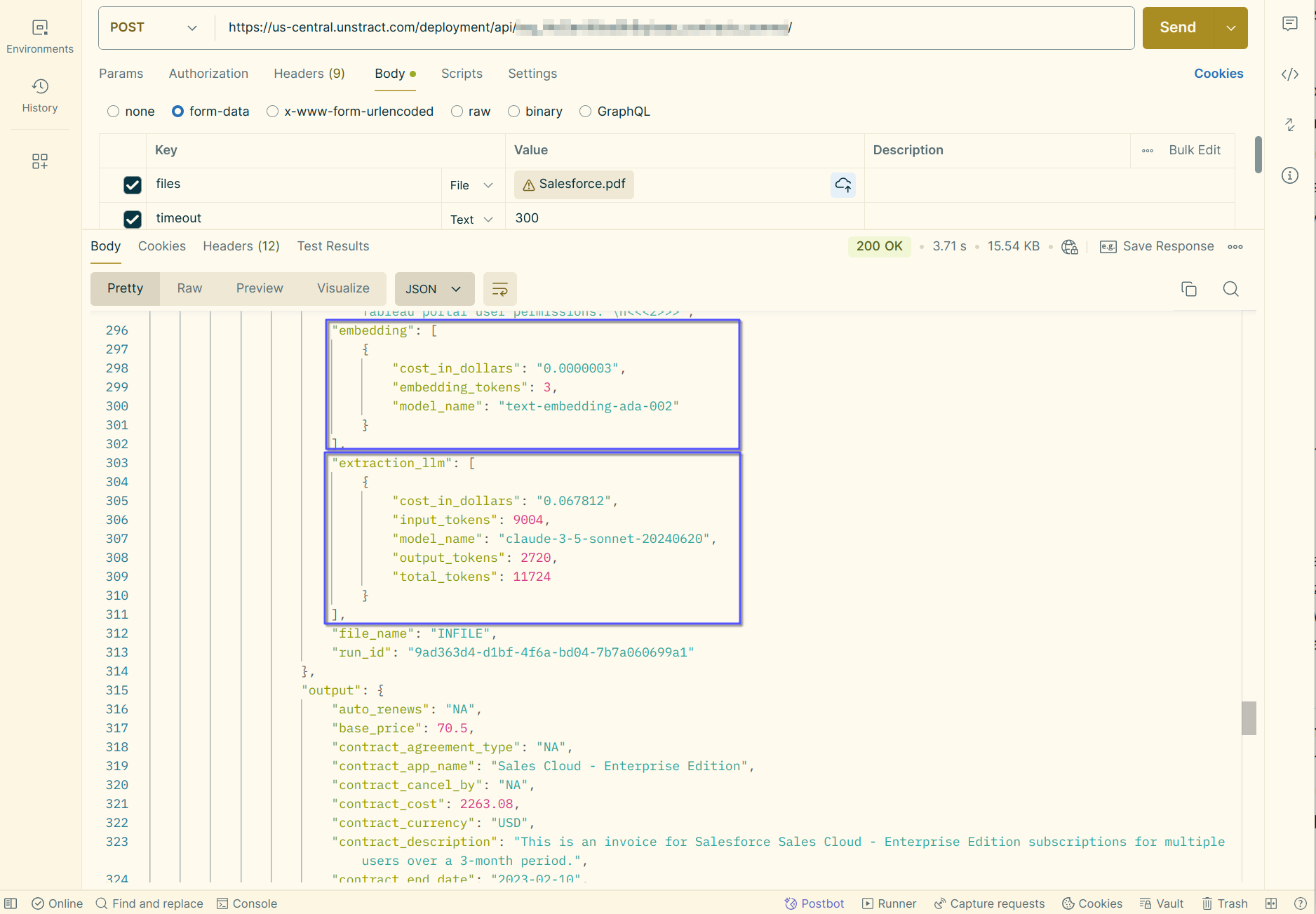
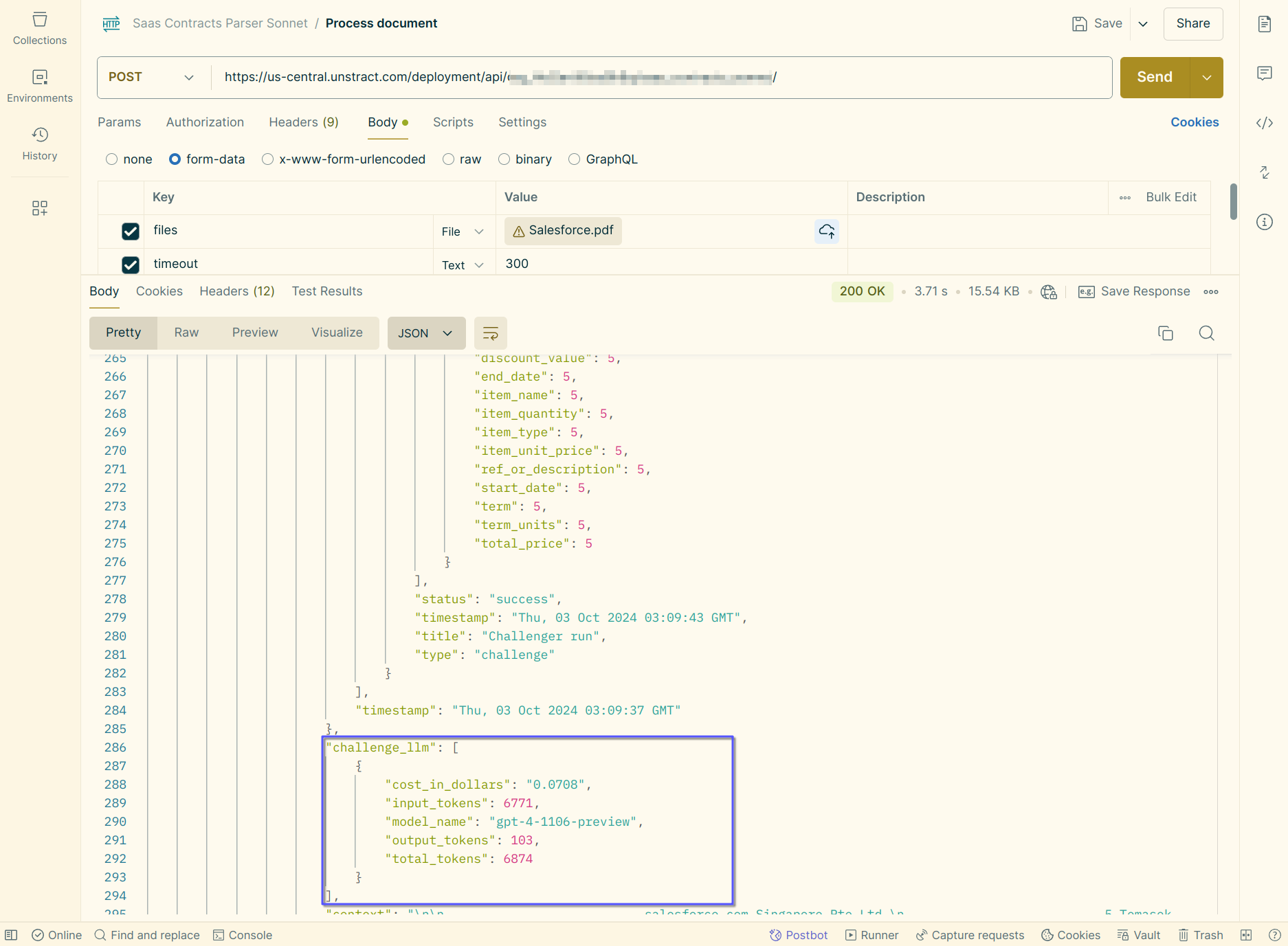
If LLMChallenge is enabled, cost for the challenger LLM, along with the tokens consumed is also made available as part of the metadata returned.
Automating batch extractions
An open source batch processing script is available that should allow easily call your deployed API endpoint against a batch of sample documents. The JSON responses from the API are saved in a SQLite database flat file, from where you can retrieve the API response JSON values and easily calculate the average cost of processing a document. Other useful information like response times, etc are also saved in the database. We recommend that you use an open source tool like DBeaver to retrieve data from the SQLite DB flat file.
Need help?
If you need help calculating costs, you can always reach out to us on the Unstract Community Slack.