Destination Configuration
This page details the configuration options available when setting up destination in your workflows. Destination configurations define where and how your processed data is stored.
File System Destination Configuration
When using a File System as your destination connector (common in Task pipelines), you can configure where processed output files are stored.
Output Folder
Specifies the folder path where processed output files will be stored. This path is relative to the root of the configured filesystem connector.
Best Practices:
- Use descriptive folder names that reflect the workflow purpose
- Consider organizing outputs by date or workflow type
- Ensure the output folder is different from input folders to avoid reprocessing
Database Destination Configuration
When using a Database as your destination connector (common in ETL and HITL workflows), you can configure how extracted data is stored in database tables.
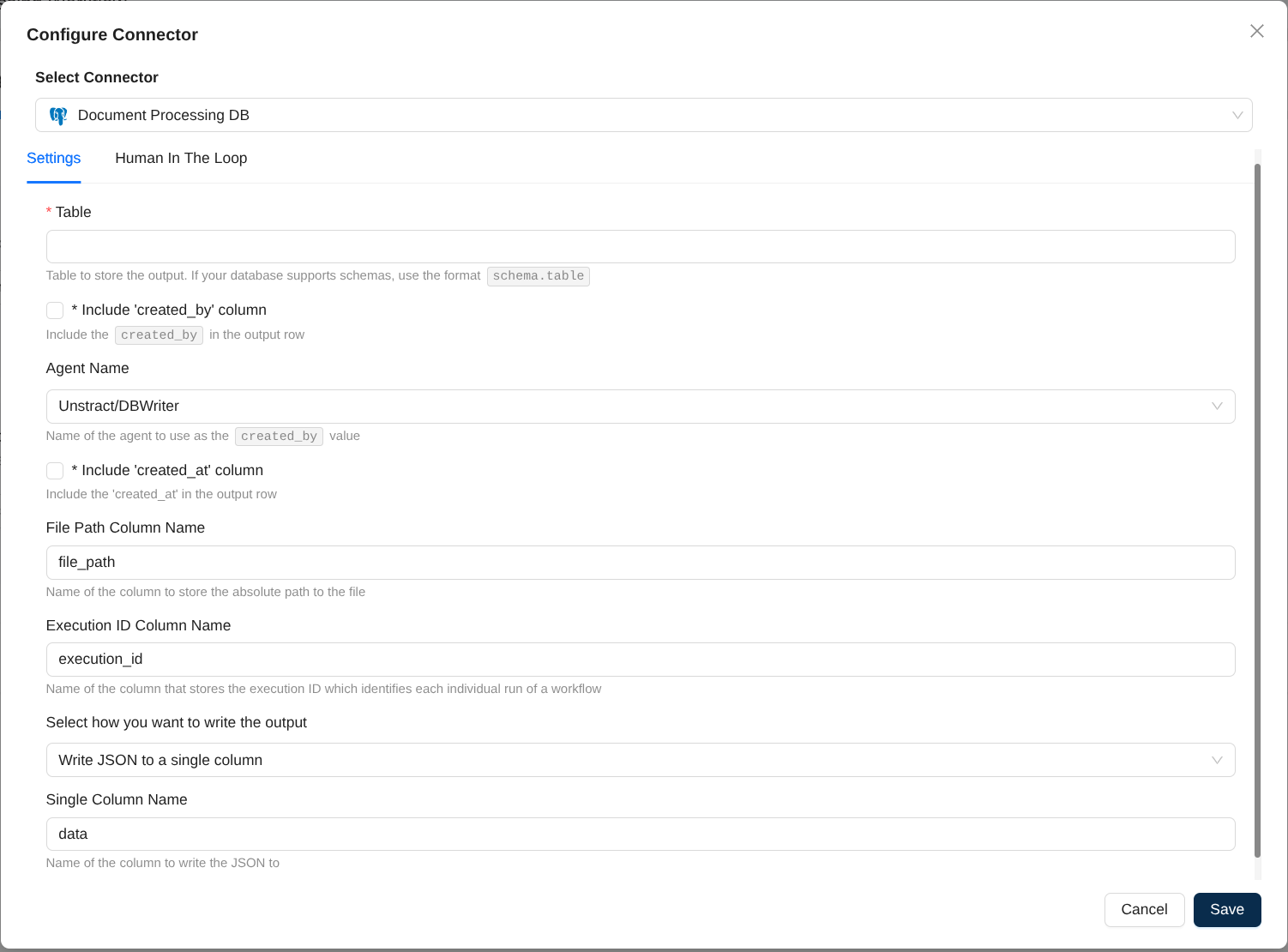
Table Name
The database table where processed output will be stored. If your database supports schemas, use the format schema.table (e.g., public.invoices or analytics.documents).
- The table will be created if does not exist with the database user configured with the connector
- If the table already exists, ensure that the database user has INSERT permissions on the table
Include 'created_by' column
When enabled, adds a created_by column to each output row, identifying the agent or process that created the record.
Agent Name
The value to use for the created_by column. Takes effect only when created_by is enabled. Defaults to "Unstract/DBWriter".
Use Cases:
- Track which workflow or process generated each record
- Enable multi-workflow auditing in shared tables
- Support compliance and data lineage requirements
Include 'created_at' column
When enabled, adds a created_at column to each output row, recording when the data was processed and inserted.
File Path Column Name
The name of the column that will store the absolute path to the source file that was processed. This helps link database records to source documents
Execution ID Column Name
The name of the column that will store the unique execution identifier for each workflow run. This ID helps track executions and is useful while debugging and viewing logs of the execution.
Select how you want to write the output
Determines how the extracted data is structured in the database table.
Available Options:
Write JSON to a single column
Stores all extracted data as a JSON object in a single database column. This is the most flexible option and is currently the primary supported format.
Single Column Name
The name of the column that will contain the JSON data
Best Practices
For Database Destinations
-
Always include audit columns in production workflows:
- Enable
created_atfor time tracking - Enable
created_byto identify the workflow
- Enable
-
Use descriptive column names that match your organization's naming conventions
-
Test table permissions before deploying:
- Ensure INSERT permissions
- Verify column data types match expected output
For Filesystem Destinations
-
Organize output folders logically:
- Use date-based folders for time series data
- Separate folders by workflow type or data category
-
Avoid output/input folder overlap to prevent circular processing
-
Plan storage capacity based on expected file volumes
Configuration Storage
All destination configuration settings are stored in the workflow's backend configuration as JSON. These settings can be modified after workflow creation by editing the workflow configuration.